What does a data scientist do?
Data scientists perform services ranging from data infrastructure design and management, to data analysis of various kinds. In my consulting I focus on the data analysis side, and in particular on so-called machine learning tasks, which is what I will discuss here.
Generally, machine learning refers to the software implementation of mathematical models that extract from historical data the information needed to respond, usually automatically, to new data instances in some way.
For example, spam filters predict whether to designate a new email as “junk”, based on how a user previously designated a large number of previous messages. A property valuation site suggests the sale price for a new home, given its location and other attributes, based on a database of previous sales.
Machine learning models are usually adaptive in the sense that new data is being continually assimilated to improve its performance over time.
Typical machine learning tasks
Here is a non-exhaustive list of tasks a data scientist can help you carry out:
-
Sales forecasting for inventory management
-
Recommender systems, e.g., for movies
-
Credit scoring and next-best offers
-
Pricing of goods and services, e.g., property and insurance policies
-
Sales forecasting for inventory management
-
Real-time selection of web-page advertising
-
Text-based sentiment analysis
-
Content relevance tasks, such as web search results
-
Fraud detection
-
Risk assessment
-
Prediction of equipment failures
-
Network intrusion detection
-
Automated message filtering/prioritisation
-
Market segmentation
The data scientist’s edge
It is difficult to implement machine learning tasks without a detailed knowledge of learning algorithms (and their limitations!) guided by a proper theoretical grounding in statistical theory.
Any experienced data scientist will tell you that no one model or algorithm is the best for all tasks. While an out-of-the-box solution may sometimes be appropriate, most models benefit significantly from careful tuning and a data scientist may try several models before settling on particular one. In an advanced technique known as stacking a data scientist may even combine several models together to gain that extra edge.
A crucial role played by the data scientist is in the interpretation of a model’s output. For a start, a poor choice of improperly trained model can easily generate garbage responses, and troubleshooting is difficult without an understanding of the model’s inner workings. For a subtler example, consider the problem of selecting a home-valuation model for a bank. One might be tempted to choose the model with the lowest error, as estimated on some test data. However, from a risk-management perspective, the bank may actually prefer a model with a larger average error, if one can associate greater certainty with the error estimate. Addressing issues such as these requires some mathematical and statistical sophistication.
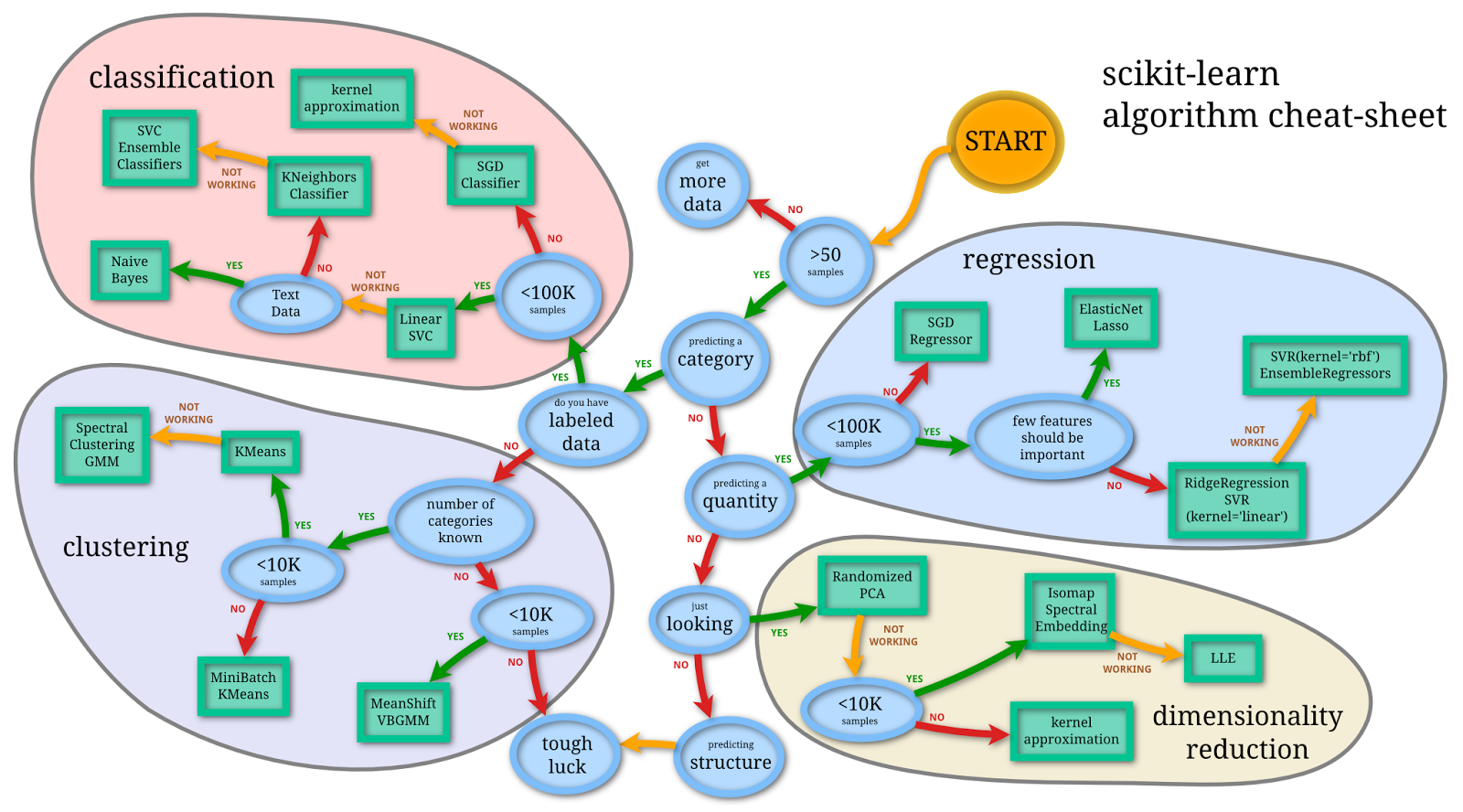
To get an idea of the complexity of model-selection, check out this (somewhat outdated) cheat-sheet from ScikitLearn (a suite of Python machine learning algorithms) originally created by Andreas Mueller:
Why the hype now?
Data science is a relatively new field because:
-
The collection of the the large amounts data needed to effectively train models has been previously limited to a small number of large enterprises. Nowadays, any operation with a web site is already routinely collecting data.
-
The computational resources needed to train (or even develop) many models was not historically available. This meant that data analysis tasks (such as credit scoring or insurance pricing, for example) relied heavily on specialised domain knowledge, ad hoc approaches, and simple (less accurate) models that were computationally inexpensive.